











selenium+beautifulsoup+pandas爬取百度学术
编辑环境
requirements:
BeautifulSoup
selenium(with headless Chrome)
pandas
BeautifulSoup用来解释html,用selenium代替requests进行请求(原因后面会讲到),用pandas存储
搜索页url
打开百度学术输入关键字回车后可以看到当前的url是
http://xueshu.baidu.com/s?wd=自然语言处理&rsv_bp=0&tn=SE_baiduxueshu_c1gjeupa&rsv_spt=3&ie=utf-8&f=8&rsv_sug2=0&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D
翻页后
http://xueshu.baidu.com/s?wd=自然语言处理&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
很容易发现,实质上请求的url应该是http://xueshu.baidu.com/s?wd=自然语言处理&pn=x(x为条数) 复制进地址框中打开发现跟刚才的是一样的,ok
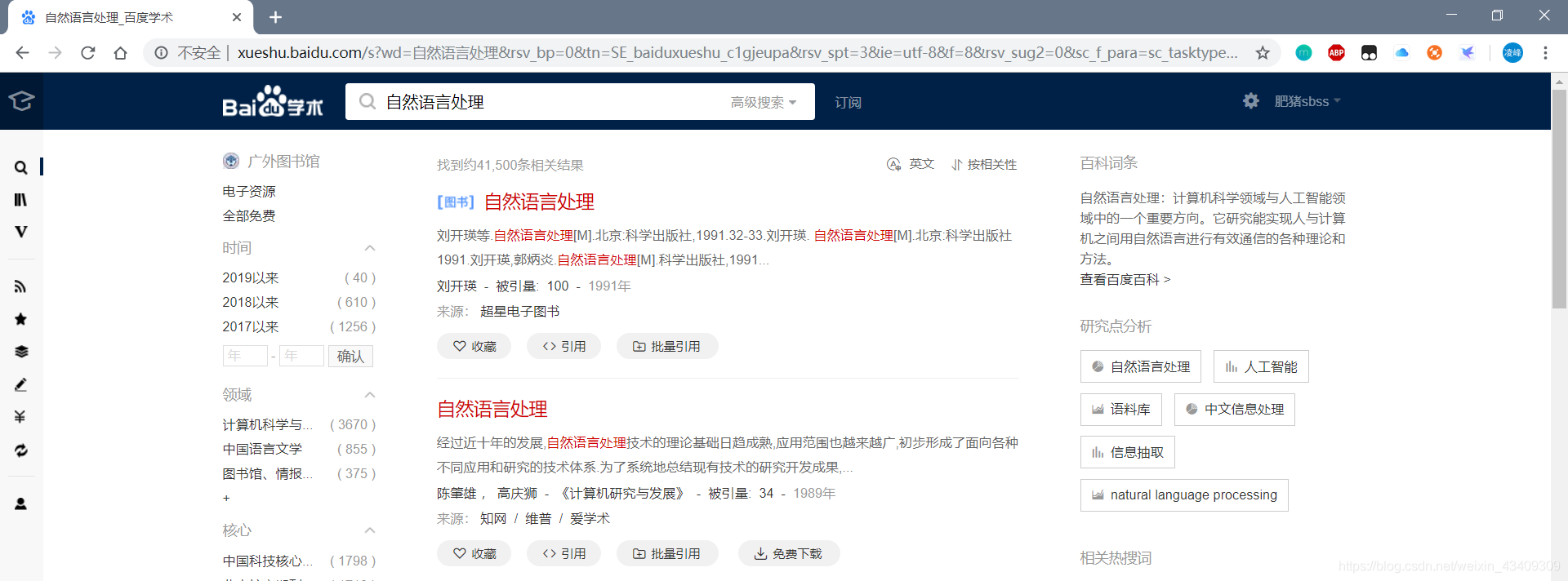
于是可以根据这个规律来构造要请求的url
# 构造请求url
url = '<http://xueshu.baidu.com/s?wd=自然语言处理&pn=>'
urls = []
for i in range(0, 210, 10):
urls.append(url + str(i))
详情页url
接下来这一部分就有一些难度了。 首先还是老办法用开发者工具看看链接所在的标签 ps:点击开发者工具左上角的鼠标工具可以快速定位页面中的元素!
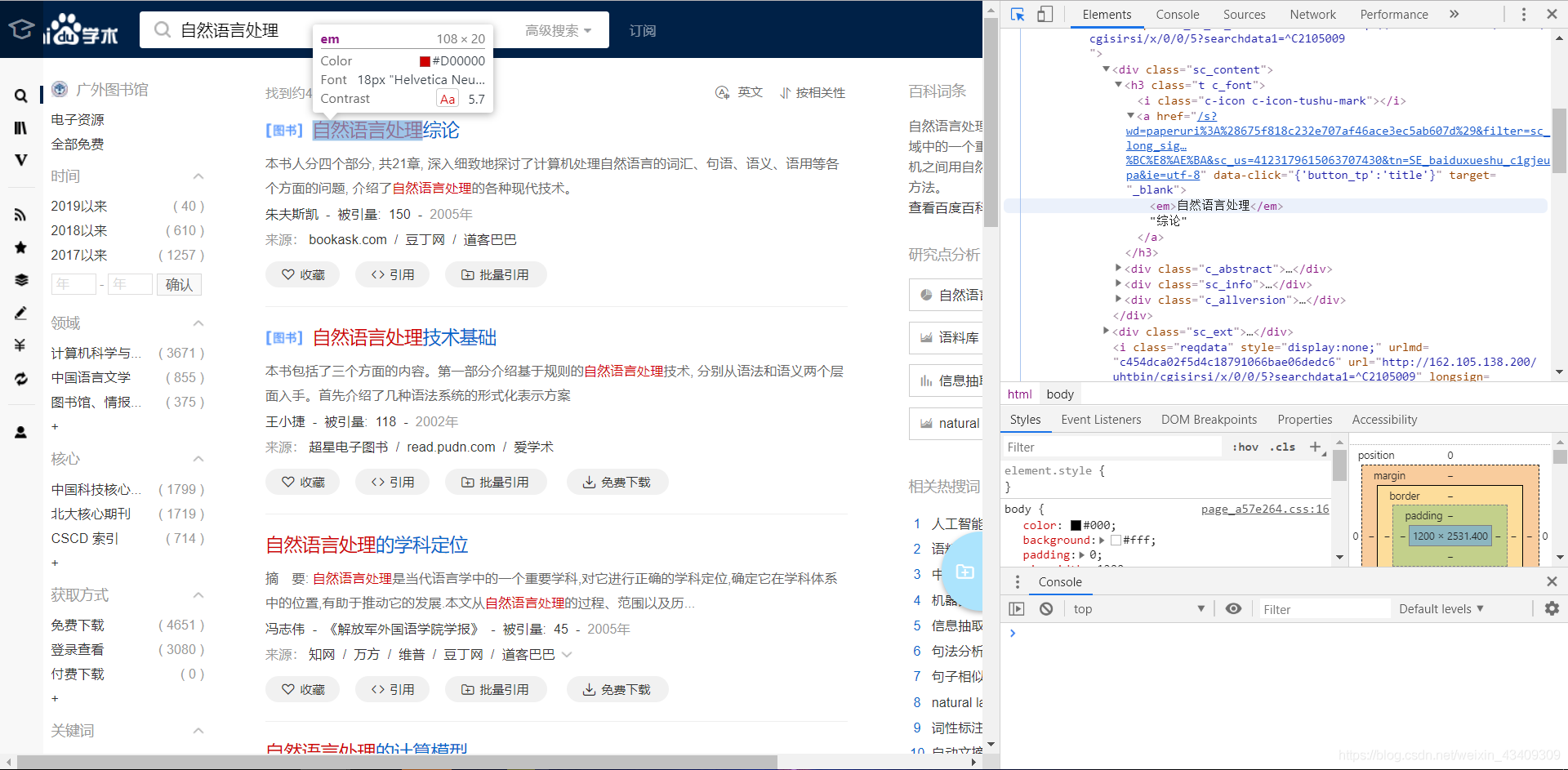
一开始觉得ok很好办 用request做就行 贴一下用request的代码
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/65.0.3325.162 Safari/537.36'
}
# 请求
html = requests.get(urls[0], headers)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'lxml')
# print(html.text)
#获取书的详情url
#匹配所有的url
book = soup.find_all(name='a', href=re.compile('/s.*?'),
attrs={'target': '_blank', 'data-click': "{'button_tp':'title'}"})
books = []
for item in book:
book_url = item.get('href')
books.append('<http://xueshu.baidu.com>' + book_url)
print(books)
这时候确实能够获取到所有的图书详情的url,但是从这个url跳转获得的页面信息是折叠的,无法获得完整的摘要等信息,这是很大的一个坑点。可能是一个简单的反爬机制。
再观察,从页面中获得的url是
http://xueshu.baidu.com/s?wd=paperuri%3A%286d66b7b4d828ef44f558745a76af01c2%29&filter=sc_long_sign&sc_ks_para=q%3D%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E6%8A%80%E6%9C%AF%E5%9F%BA%E7%A1%80&sc_us=6796286780419649144&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8
实际点击打开之后的url是
http://xueshu.baidu.com/usercenter/paper/show?paperid=6d66b7b4d828ef44f558745a76af01c2&site=xueshu_se
说明中间还发生了跳转,如果直接请求上一个url不能获得完整的页面信息 那如何获得真正的url呢?用selenium
Selenium是啥? Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
selenium和Chromedriver的安装部署可以参考 https://www.cnblogs.com/technologylife/p/5829944.html
然后就可以开始用selenium进行请求了,贴一下代码
from selenium import webdriver
from bs4 import BeautifulSoup
from lxml import etree
# 使用headless Chrome(phantomjs不可用)
option = webdriver.ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=option)
driver.set_window_size(1920, 1080)
def get_page(url):
# 打开网页
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml') # 同样用beautifulsoup对html进行处理
# 得到原始url
soup = str(soup)
html = etree.HTML(soup)
ori_urls_a = html.xpath('//div[@class="sc_content"]/h3/a/@href') # 用xpath进行选择
ori_urls = []
for url in ori_urls_a:
ori_urls.append('<http://xueshu.baidu.com>' + url)
for url in ori_urls:
driver.get(url)
real_url = driver.current_url
print(real_url)
然后就可以得到真正的url了!
获取图书详情
这一步比较简单,还是用beautifulsoup就行了,贴一下代码
# -*- coding:utf-8 -*-
import requests
import re
from bs4 import BeautifulSoup
from selenium import webdriver
url = '<http://xueshu.baidu.com/usercenter/paper/show?paperid=7a211369a1fe18201be234ffb82622c1&site=xueshu_se>'
# 请求
# 使用headless Chrome
option = webdriver.ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=option)
driver.set_window_size(1920, 1080)
def get_book_detail(url):
# 先访问原url
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
flag = 1
# 先初始化成全局变量
name = ''
author_list = []
abstract = ''
keyword_list = []
ref_num = 0
# 书名
try:
name = soup.find(name='a', target='_blank',
attrs={'data-click': "{'act_block':'main','button_tp':'title'}"}).text
except:
name = None
flag = 0 # 奇怪的标题 放弃该数据
finally:
print(name)
if (flag == 1):
# 作者
# 此处作者需要用class来筛选避免选中下面参考文献中的作者
try:
authors = soup.find_all(name='a', target='_blank',
attrs={'data-click': "{'button_tp':'author'}", 'class': ''})
author_list = []
for author in authors:
pattern = re.compile('[\\u4e00-\\u9fa5]{2,4}') # 正则表达式取出中文名
author_name = pattern.findall(author.text)[0]
author_list.append(author_name)
except:
authors = None
finally:
print(author_list)
# 摘要
# 此处需要作异常处理 遇到摘要为空时输出None
try:
abstract = soup.find(attrs={'class': 'abstract'}).text
except:
abstract = None
finally:
print(abstract)
# 关键词
try:
url_pat = re.compile('^http://xueshu.baidu.com/.*?ie=utf-8$')
keywords = soup.find_all(name='a', target='_blank', attrs={'href': url_pat, 'class': ''})
for keyword in keywords:
keyword_list.append(keyword.text)
except:
keyword_list = None
finally:
print(keyword_list)
# 被引量
ref = soup.find(name='a', target='_blank', attrs={'class': "sc_cite_cont"}).text
ref_pat = re.compile('[0-9]{1,4}')
ref_num = ref_pat.findall(ref)[0]
print(ref_num)
else:
print("SKIPPED")
return {'name': name, 'authors': author_list, 'abstract': abstract, 'keyword': keyword_list, 'ref': ref_num}
if __name__ == '__main__':
get_book_detail(url)
PS: 要注意其中有一些信息可能会为空,因此需要做异常处理,保证脚本能够一直跑下去,同时跳过一些奇怪的数据。
pandas存储
最后,将数据用pandas存成csv或者xsl。 pandas的使用可以参考官方手册或者 https://blog.csdn.net/weixin_41666747/article/details/80249548 (简单版)
主要是Series(序列)和Dataframe(数据帧)两种数据结构 了解到只需要用列表嵌套字典的方法将数据传进去,用pd.DataFrame方法就可以将数据转换成一个二维数据结构。
最后步骤比较简单,贴下代码
import pandas as pd
res = []
for url in urls:
res += bd.get_page(url)
columns = ['name', 'authors', 'abstract', 'keyword', 'ref']
df = pd.DataFrame(res, columns=columns)
df.to_excel('b.xls', encoding='utf-8') # xsl
df.to_csv('b.csv', encoding='utf-8') # csv
PS: 最后指定encoding=utf-8可以避免一些编码上的问题(习惯),但是直接保存为csv之后用Excel打开可能会出现乱码,这时候只需要用记事本打开csv然后另存为,选择utf-8再用Excel打开就可以正常显示了。
- 0
- 0
-
赞助
 微信赞赏码
微信赞赏码
-
分享