











猫鱼周刊 vol. 017 LLM 该怎么落地?
编辑关于本刊
这是猫鱼周刊的第 18 期,本系列每周日更新,主要内容为每周收集内容的分享,同时发布在
博客:阿猫的博客-猫鱼周刊
RSS:猫鱼周刊
邮件订阅:猫鱼周刊
微信公众号:猫兄的和谐号列车
Discord:猫兄的和谐号高铁
{kind=link}
前言
猫鱼周刊自从去年 11 月开始更新以来,很少有缺勤,每周日(有一两次好像是周一才发)都会更新,上周缺了一周,主要是两个原因:一是我身体有点问题,周末两天基本都在医院里,太累了,实在没抽出时间写;二是上周工作比较忙没怎么冲浪,没收集到什么特别好的素材,宁可不发也不想凑数。
另外一个事是,做周刊几个月了,除了博客有寥寥几条评论,没怎么收到读者的反馈,很想听听大家的反馈,正面的反馈能激励我继续创作,负面的反馈能帮助我改进不足,另外我也很喜欢交流分享,所以建了一个微信交流群,感兴趣可以进来聊天吹水。

文章
开始介绍这周的几篇文章前,我想先分享一下我使用大模型的经历。
从 23 年 11 月 OpenAI 发布 GPT-3.5-Turbo 模型,到 23 年 3 月 OpenAI 发布 GPT-4 模型,再到往后各家公司纷纷推出自己的 LLM,以及 Midjourney、DALL-E、Stable Diffusion 等等大模型的发布,去年似乎是大模型井喷的一年,也有人称之为 AIGC 元年。这一年也涌现出非常多 AI 相关的应用,我自己体验下来,有长久使用的只有以下几个:
- GPT 的 API,目前最喜欢 gpt-4-turbo-preview,比 3.5 精准,比 4 快,价格便宜
- GitHub Copilot,生成懒得打的内容,帮忙改 bug,根据注释引导写我不会的代码
- 一些 LLM 的聊天界面,这个比较多,现在用的 OpenCat,原生应用还是舒服
- ollama,最近刚开始探索,本地跑一些开源的大模型
我自己也造过一个命令行的应用,GitHub - LeslieLeung/PTPT: Let ChatGPT handle Plain Text for you! 让 ChatGPT 替你处理纯文本文件!,不过效果一般(主要是没有获得什么用户),就没怎么维护,自己也用得不是很多。
过去一年里,我围绕“大模型的落地”做过很多思考,在企业应用中也做过一些尝试,不过收效甚微。正巧最近开始重拾一点对大模型的兴趣,找到了些比较好的资料,分享一下。除了周刊里的这两个,我在去年也收集过一些 LLM 相关的资源,也可以一看:资源 | My Awesome LLM。
2024 年,基于大模型的 Agent 如何在企业落地?
从 toB、toC 等方向讲解了 Agent(智能体)的发展方向。篇幅较长,但对各个方面都介绍得比较全,值得一看。这个作者真的体验了非常多大模型相关的产品,也有比较独到的思考。
LLM 应用开发实践笔记
也是上文作者写的一本小书(笔记),内容蛮多,可以看看。
我的老婆确诊肺癌,希望能得到你的帮助
一个程序员在爱人确诊肺癌后,写下的一篇记录文章,目的是收集相关的资讯,以及将经历分享给类似经历的人。
我非常敬佩这个作者,首先是能保持理性的思维,在人生剧变中以理性、平稳的心态面对困难;其次是很开源范的信息处理方式,广泛收集意见、公开信息。
项目
teableio/teable

一个以 Postgres 为底层的无代码数据库,提供了一个类似 Notion 数据库的前端界面,以及 API 和数据库连接。
它比较新颖的点是,底下的 Postgres 数据库可以直接对开发者暴露,比起 airtable 之类的产品有更多可玩性和灵活性。
leafac/kill-the-newsletter

GitHub - leafac/kill-the-newsletter: Convert email newsletters into Atom feeds
一个能把邮件订阅转成 RSS 的工具。原理是提供一个类似临时邮箱的东西,然后帮你转成一个 Atom Feed,使用上比较简单,使用它给的邮箱去订阅就行了。
工具/网站
在线词源学词典
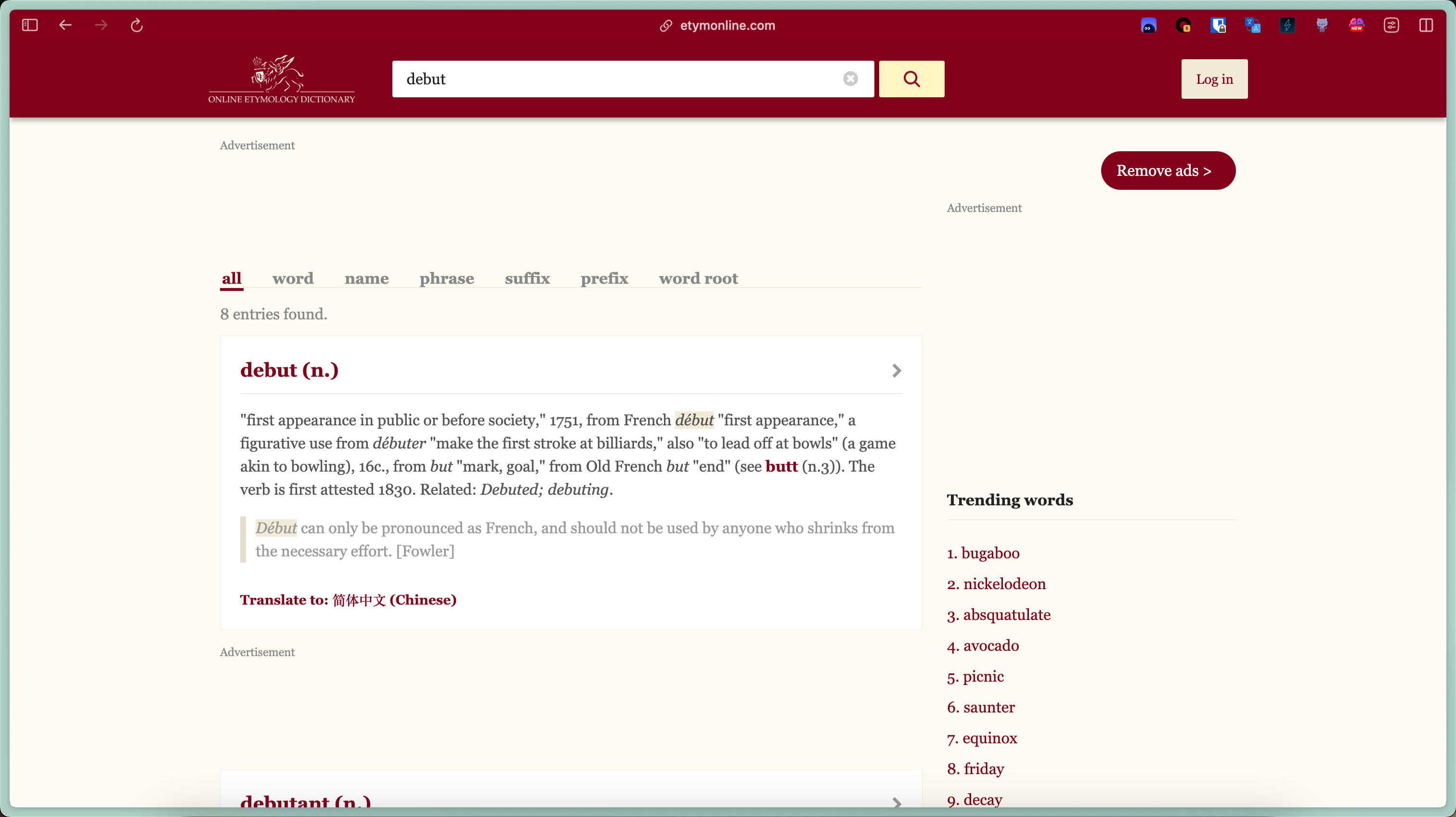
词源学就是通过解读一些古代文本以及比较其他种类的语言,研究一种语言的产生、变化和消亡,语源学致力于揭示词语的历史。
找到这个网站源于有一次我跟朋友讨论中国人最容易发错音的一些英语单词,我认为一些由法语演变来的英语词汇特别容易发错(例如 queue, debut, realm 等等),因此好奇去寻找这些词的来源,找到了这个网站,果不其然这些词都是来源于古法语。
需要注意的是,英语其实是很多种语言的大杂烩,现代英语比较主要的成份包括拉丁语、法语等,具体就是语言学的研究范畴了,为了不误导各位,建议可以自行查看英语 - 维基百科,自由的百科全书。
- 0
- 0
-
赞助
 微信赞赏码
微信赞赏码
-
分享